PWA系列 -- Fetch 技术
2018-12-11
# 背景信息
XMLHttpRequest 是微软在 IE5 提供的一个接口,使得 JS 可以在不刷新整个页面的前提下向服务器异步请求数据。它随后被 Mozilla、Apple 和 Google 采纳。W3C 从2006年也开始对它进行了标准化,提出了 XMLHttpRequest Level 1和 XMLHttpRequest Level 2。 XMLHttpRequest Level 1 在2006年完成标准草案,主要存在以下缺点:
- 受同源策略的限制,不能发送跨域请求;
- 不能发送二进制文件(如图片、视频、音频等),只能发送纯文本数据;
- 在发送和获取数据的过程中,无法实时获取进度信息,只能判断是否完成;
XMLHttpRequest Level 2 在2008年完成标准草案,新增了以下功能:
- 可以发送跨域请求,在服务端允许的情况下;
- 支持发送和接收二进制数据;
- 新增formData对象,支持发送表单数据;
- 发送和获取数据时,可以获取进度信息;
- 可以设置请求的超时时间;
从上述信息可以看到,XMLHttpRequest 可以提供完备的功能,是 Ajax 的关键技术,可以局部交换客户端及服务器之间的数据,从根本上保证了 Web 页面的动态性。而本文重点讨论的是一个更加强大的技术 ServiceWorker Fetch API。 本文主要面向前端开发者和客户端开发者,文章会在面向客户端开发者的内容上加以说明,未说明的内容则适用全部开发者。读者可以根据自身需求或兴趣选择性阅读。
# Fetch 参数说明
Fetch API 的 Request 有几种模式(Request.mode),
- same-origin — 如果一个请求是跨域的,会返回一个错误,这样确保所有的请求遵守同源策略。
- no-cors — 允许不带 CORS 头部跨域请求资源,但请求的方法只限定为 HEAD, GET 或 POST。如果 ServiceWorkers 拦截了这些请求,它们不能添加或修改除了这些之外的请求头。另外,JS 不允许访问 Response 对象的属性,这确保 ServiceWorkers 不会影响 Web 的语义,并防止由于跨域泄露数据而导致的安全和隐私问题。
- cors — 允许附带 CORS 头部跨域请求资源,例如访问第三方提供的 API 以获取资源。这些请求都需要遵守 CORS 协议,并且只有部分 Headers 暴露给 Response,但 Body 是可读的。
- navigate — 支持 navigation 请求,即跳转的目标地址为 HTML 文档的请求。参考 Chrome 49: New value "navigate" for Request.mode
Request 的 credentials 属性决定了是否允许跨域访问 Cookie,与 XHR 的 withCredentials 类似。它也有几种模式,
- omit: 不允许发送 Cookie,属于 Fetch 请求的默认行为。
- same-origin: 如果 URL 与调用的 JS 同源,则允许发送 Cookie,否则就不允许。
- include: 允许发送 Cookie,跨域请求也允许。
Request 的 cache 属性决定了 Fetch 请求与内核 HTTP cache 交互的模式,
- default — 默认情形,内核会以下面方式使用 HTTP cache,
- 如果命中 HTTP cache 并且资源是 fresh 的,会直接使用 cache。
- 如果命中 HTTP cache 并且资源是 stale 的,内核会发起条件请求,如果服务器回应资源未有修改,则直接使用 cache,否则会下载资源和更新 cache。
- 如果没有命中 HTTP cache,内核会发起普通请求,下载资源和更新 cache。
- no-store — 内核忽略 HTTP cache,直接向服务器请求资源,资源下载成功后也不会更新 HTTP cache。
- reload — 内核忽略 HTTP cache,直接向服务器请求资源,但资源下载成功后会更新 HTTP cache。
- no-cache — 内核会以下面方式使用 HTTP cache,
- 如果命中 HTTP cache 并且资源是 fresh/stale 的,内核会发起条件请求,如果服务器回应资源未有修改,则直接使用 cache,否则会下载资源和更新 cache。
- 如果没有命中 HTTP cache,内核会发起普通请求,下载资源和更新 cache。
- force-cache — 内核会以下面方式使用 HTTP cache,
- 如果命中 HTTP cache 并且资源是 fresh/stale 的,会直接使用 cache。
- 如果没有命中 HTTP cache,内核会发起普通请求,下载资源和更新 cache。
- only-if-cached — 内核会以下面方式使用 HTTP cache,
- 如果命中 HTTP cache 并且资源是 fresh/stale 的,会直接使用 cache。
- 如果没有命中,会返回错误。
- 这个模式只允许在 Request.mode = "same-origin"时使用。
Request 或 Response 的 headers 属性,返回一个 Headers 对象,有一个特殊的 guard 属性,取值如下,
| 值 | 说明 |
|---|---|
| none | 默认值 |
| request | Request.headers 对象只读 |
| request-no-cors | Request.headers 对象在 no-cors 模式下只读 |
| response | Response.headers 对象只读 |
| immutable | 所有 Header 对象都为只读 |
Request 的 redirect 属性在 Chrome 46版本实现支持,取值如下,
| 值 | 说明 |
|---|---|
| follow | 出现重定向时,使用 Location URL 作为请求 URL,继续请求 |
| error | 出现重定向时直接抛出异常 |
| manual | 出现重定向时不会抛出异常,但会得到一个 type 为 opaqueredirect 的 Response。该 Response 的状态码为0,响应头为空,Body 为空 |
Response 的 redirected 属性标记请求是否有经过跳转。 Response 的 type 属性标记响应的类型,取值如下,
| 值 | 说明 |
|---|---|
| basic | 同源请求的响应,除了 Set-Cookie/Set-Cookie2 之外,所有的响应头都可访问 |
| cors | 跨域请求的响应,只有特定的头部才允许访问,比如,Cache-Control,Content-Type |
| error | 网络出错的响应,该 Response 的状态码为0,响应头为空,Body 为空 |
| opaque | Request 的 mode 设置为 no-cors 的跨域请求的响应,该 Response 的状态码为0,响应头为空,Body 为空 |
| opaqueredirect | Request 的 redirect 属性设置为 manual 的响应,该 Response 的状态码为0,响应头为空,Body 为空 |
Request/Response的bodyUsed 属性用于标记 Body 是否已被读取过。Request 和 Response 的 body 只能被读取一次,如果需要重复读取,必须在读取之前调用 clone 获取到一个克隆对象。
# Fetch 基本流程
本节内容涉及到内核流程,读者可以根据自身需求选择性阅读。
- 正常 Fetch 流程
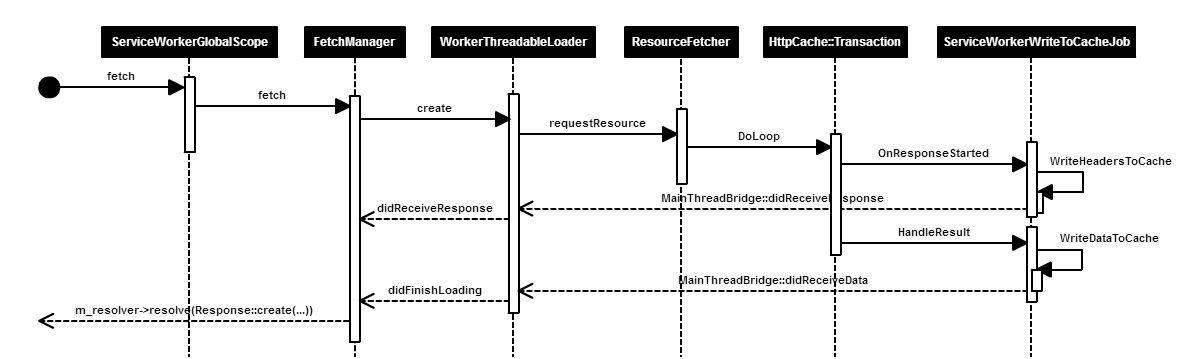
ServiceWorkers 的 Fetch,是通过 ServiceWorkerGlobalScope.idl 暴露给页端使用。其中,FetchManager 是各类 Fetch 的入口和出口,WorkerThreadableLoader 管理 worker 线程的资源请求,接着会走到 ResourceFetcher 和 HttpCacheTransaction,往下走到网络或者被拦截,响应会经过 ServiceWorker 的缓存处理模块,比如,ServiceWorkerWriteToCacheJob。
- 跨域检查不通过的流程
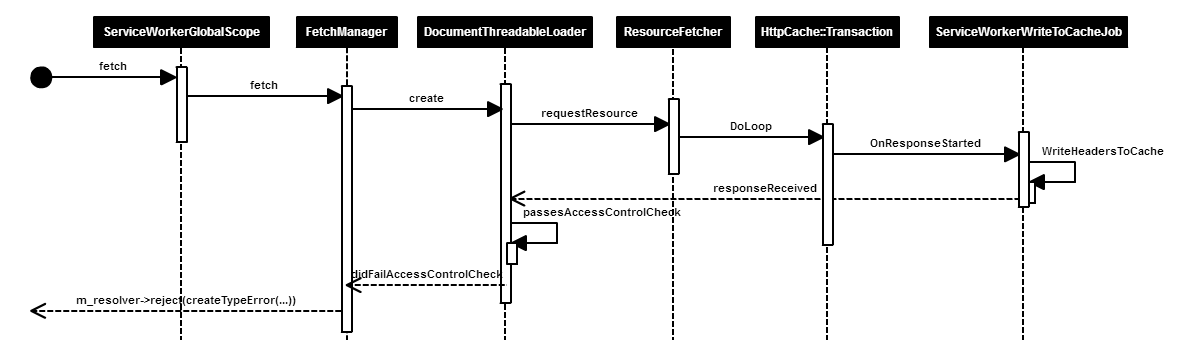
ServiceWorkers 的 Fetch,收到响应后,会在 DocumentThreadableLoader 进行跨域检查,JS 执行时(ScriptLoader::executeScript)也会进行跨域检查,如果检查不通过,会出现 “TypeError: Failed to fetch.” 之类的错误。 注1,想了解基本的 Fetch 流程,读者可自行检索文章 - Introduction to fetch()。 注2,想了解如何使用 Fetch 技术搭建离线应用,读者可自行检索文章 - The Offline Cookbook。
# Fetch 请求拦截
# 页端拦截
页端 JS 可以监听 Fetch 事件,通过 FetchEvent.respondWith 返回符合期望的 Response,即通过拦截 Response 而达到控制存储策略的目的。一般来说,有以下几种方式,
- 仅使用 Cache
self.addEventListener('fetch', function(event) {
// If a match isn't found in the cache, the response
// will look like a connection error
event.respondWith(caches.match(event.request));
});
- 仅使用网络
self.addEventListener('fetch', function(event) {
event.respondWith(fetch(event.request));
// or simply don't call event.respondWith, which
// will result in default browser behaviour
})
- 优先使用缓存,失败则使用网络
self.addEventListener('fetch', function(event) {
event.respondWith(
caches.match(event.request).then(function(response) {
returnresponse || fetch(event.request);
})
);
});
- 缓存与网络竞争,谁快就用谁
// Promise.race is no good to us because it rejects if
// a promise rejects before fulfilling. Let's make a proper
// race function:
function promiseAny(promises) {
returnnewPromise((resolve, reject) => {
// make sure promises are all promises
promises = promises.map(p => Promise.resolve(p));
// resolve this promise as soon as one resolves
promises.forEach(p => p.then(resolve));
// reject if all promises reject
promises.reduce((a, b) => a.catch(() => b))
.catch(() => reject(Error("All failed")));
});
};
self.addEventListener('fetch', function(event) {
event.respondWith(
promiseAny([
caches.match(event.request),
fetch(event.request)
])
);
});
- 优先使用网络,失败则使用缓存
self.addEventListener('fetch', function(event) {
event.respondWith(
fetch(event.request).catch(function() {
returncaches.match(event.request);
})
);
});
- 先使用缓存,再访问网络更新缓存,等同于后置验证
Code in the page:
var networkDataReceived = false;
startSpinner();
// fetch fresh data
var networkUpdate = fetch('/data.json').then(function(response) {
returnresponse.json();
}).then(function(data) {
networkDataReceived = true;
updatePage();
});
// fetch cached data
caches.match('/data.json').then(function(response) {
if(!response) throwError("No data");
returnresponse.json();
}).then(function(data) {
// don't overwrite newer network data
if(!networkDataReceived) {
updatePage(data);
}
}).catch(function() {
// we didn't get cached data, the network is our last hope:
returnnetworkUpdate;
}).catch(showErrorMessage).then(stopSpinner);
Code in the ServiceWorker:
self.addEventListener('fetch', function(event) {
event.respondWith(
caches.open('mysite-dynamic').then(function(cache) {
returnfetch(event.request).then(function(response) {
cache.put(event.request, response.clone());
returnresponse;
});
})
);
});
- 常规的回退流程,在缓存和网络都不可用时,可以提供一个默认页面
self.addEventListener('fetch', function(event) {
event.respondWith(
// Try the cache
caches.match(event.request).then(function(response) {
// Fall back to network
returnresponse || fetch(event.request);
}).catch(function() {
// If both fail, show a generic fallback:
returncaches.match('/offline.html');
// However, in reality you'd have many different
// fallbacks, depending on URL & headers.
// Eg, a fallback silhouette image for avatars.
})
);
});
注,本节内容来自官方文档 The Offline Cookbook
# 客户端拦截
本节内容适合客户端开发者,读者可以根据自身需求选择性阅读。 一般来说,基于 WebView 的 Hybrid Apps 实现离线的方式是,提前将资源下载到客户端,在页面发起资源请求时,客户端就可以在 WebViewClient.shouldInterceptRequest 接口进行拦截,使用本地资源构造相应的 Response,让其优先使用本地资源,从而实现离线的功能。但是,ServiceWorker 的请求并不会和具体的 WebView 关联,即不会在 WebViewClient.shouldInterceptRequest 接口回调,那么我们如何进行 ServiceWorker fetch 请求的拦截呢? Android7.0(Chromium49)提供了 ServiceWorkerController.shouldInterceptRequest 接口,专门用于拦截 ServiceWorker 的请求。拦截的流程如下, 客户端拦截的代码示例
ServiceWorkerController swController = ServiceWorkerController.getInstance();
swController.setServiceWorkerClient(newServiceWorkerClient() {
@Override
publicWebResourceResponse shouldInterceptRequest(WebResourceRequest request) {
// Capture request here and generate response or allow pass-through
// by returning null.
returnnull;
}
});
# 备注说明
- 问题:Fetch 请求不能取消,读者可自行检索文章 - Add timeout option for fetch?
- 问题:Fetch 请求无法获取进度,读者可自行检索文章 - Progress indicators for fetch?
# Fetch 未来展望
XMLHttpRequest Level 2 对 XMLHttpRequest 进行了扩展,增加了发送跨域请求,收发二进制数据,可以设置超时时间,等等特性。那么,我们为什么需要新增 Fetch API,而不是继续扩展 XHR 呢?XMLHttpRequest 虽然非常强大,但也并不完美,它在设计上存在缺陷,不符合职责分离原则,输入、输出和结果处理都混杂在一个对象里面,会存在回调嵌套问题。 Extensible Web Manifesto 组织的宣言里面提到可扩展 Web 的设计原则,着重于增加安全高效的底层能力,其中 Fetch API 就属于符合这种能力要求的 API,它致力于向 JS 引入和 HTTP 协议的Request/Response 同样的原语,属于一种非常底层的能力。 Fetch API 是一个面向未来的 API,既现代又底层,有很多非常优雅的特性,Promise-based,Request/Response primitives,Support Streams,等等。这样的 API,当然不期望背负太多的历史包袱。虽然它现在也还不完善,比如存在无法获取进度,请求不能取消,等等问题,但这些问题终究能被解决,而且将来还可能会继续提供越来越强大的特性,比如目前 Chromium 已支持的 Foreign Fetch。
