How cc Works 中文译文
2019-01-24
# 背景
Chromium 的工程师们写了两篇技术文章 How Blink Works 和 How cc Works,分别介绍了 Chrome 浏览器内核内部的两个重要模块 Blink 和 cc 内部设计和实现的一些细节。对于想要了解 Chromium 内核内部实现的同学,这两篇文章提供了不错的入门指引。在征得作者同意后,我将其翻译成中文,以馈读者。 文中部分术语觉得难以翻译成合适的中文的,我会保留原文。对于一些较为复杂的概念会根据自己的理解给出一些额外的解释。如果有我理解有误,没有正确翻译的地方,也请读者留言指出。 另外,How cc Works 的内容比较深,要看明白这篇文章的内容,多少需要对网页渲染有一定的了解,起码需要理解光栅化,合成,图层,分块这些概念,需要理解软件合成和 gpu 合成,软件光栅化和 gpu 光栅化的区别。 Chromium 目前实际支持三种不同的光栅化和合成的组合方式:软件光栅化 + 软件合成,软件光栅化 + gpu 合成,gpu 光栅化 + gpu 合成。在移动平台上,大部分设备和移动版网页使用的都是 gpu 光栅化 + gpu 合成的渲染方式,理论上性能也最佳。
# tl;dr
cc/ 因为历史原因被称为 Chrome Compositor,但目前已经不太准确。它既不是唯一的 chrome compositor(当然我们有很多个),甚至可以说不再是合成器。 danakj 建议使用 “content collator” 作为替代名称。 在 browser 进程,cc 是在 ui/compositor 或 Android 平台相关的代码中被使用,在 mus utility 进程中,它是在 ui/compositor 中被使用。cc 也通过 Blink/RenderWidget 嵌入到 renderer 进程中。cc 负责从它的 embedder 中获取绘制输入,找出它们在屏幕上呈现的位置,根据绘制输入生成对应的 gpu 纹理,包括光栅化,图片解码,运行图片动画,最终以 compositor frame 的方式将这些纹理转发给 display compositor。cc 还处理从 browser 进程转发的输入事件,在不涉及 Blink 的情况下,可以及时地处理双指缩放和滚动手势。
[译注] Chromium 的合成器架构在最近和未来的一段时间变化很大,总的说来真正负责合成的部分已经迁移到 viz,目前 display compositor 位于 viz(viz 运行在 viz 进程,也就是以前的 gpu 进程)。cc 从目前的定位来看是作为 viz client 而存在,将不同的绘制内容来源转换成用于最终合成的输入,也吻合了上面的 "content collator" 的称谓。不过如果能够接受 layer compositor 这种 virtual compositor 的概念的话,cc 目前仍然保有这部分功能,继续将其称为合成器也未尝不可,特别是从页端的角度来理解合成器,对应的仍然是 cc。
# 进程/线程架构
cc 可以被 embedders 以单线程或者多线程的方式使用。单线程版本的额外开销较小。多线程版本会有延迟开销,但允许在一个线程繁忙时,另外一个线程可以及时地处理输入事件和动画。 通常 browser 使用单线程版本,因为它的主线程任务更简单负荷更轻量,而 renderer 使用多线程版本,因为它的主线程(Blink)在某些页面上可能非常繁忙。 单线程和多线程版本都使用 cc::Scheduler 来驱动自己,它决定了何时提交帧。 一个例外(第三种模式仅在这个地方使用)是 Blink layout 测试和 sim 测试,它们不会(总是)使用 Scheduler,而是通过 LayerTreeHost::Composite 直接请求 cc 同步地合成输出。 这是出于历史原因,并且也是测试过程需要更直接的控制。
# 内容绘制数据流动概览
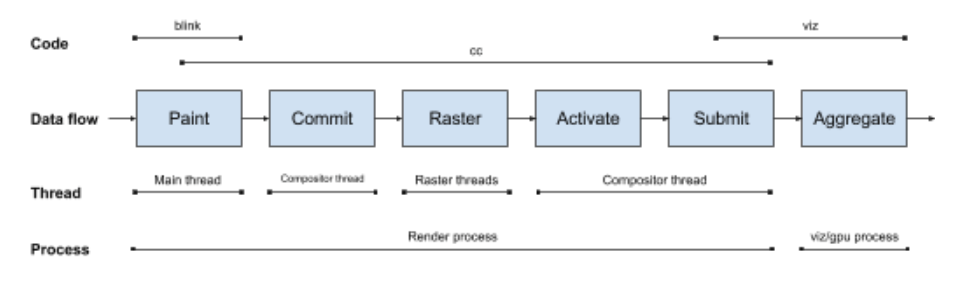
embedders 调用 cc 的主要接口是通过 LayerTreeHost(使用不同的 LayerTreeSettings 设置项创建)和一棵图层树。 图层是一个包含内容的矩形区域,包括描述该内容应如何在屏幕上呈现的各种属性。 cc 负责将该内容的绘制表示(也就是 PaintRecord)转换为光栅化表示(software 位图或 gpu 纹理)并确定该矩形在屏幕上的显示位置。 cc 通过 PropertyTreeBuilder 将此图层树输入转换为一组属性树,并将图层树简化为可见图层的有序列表。作为 slimming paint 项目的一部分,Blink 将直接设置属性树和图层列表,而不是通过更原始的图层树接口,从而避免渲染流水线在这部分上的耗时。 在提交过程中,cc 将所有来自主线程的数据结构输入转换成合成器线程的数据结构。此时,cc 确定每个图层的哪些部分可见,然后继续解码图片和光栅化内容。一旦所有内容准备好出现在屏幕上,cc 就会 activates 已提交的树,然后就可以“绘制”它。 不幸的是,cc 仍然在许多地方使用 “draw” 和 “swap” 的称谓,尽管事实上它不再是真正的“绘制”和“前后缓冲区交换”。 cc 中的 “Draw” 意味着构造一个包含 quads 和 render passes 的 compositor frame,以便在屏幕上最终绘制。 cc 中的 “Swap” 则意味着通过 CompositorFrameSink 将该帧提交给 display compositor。这些帧被发送到 viz 的 SurfaceAggregator,在那里所有来自不同的帧生产者的 compositor frame 被聚集在一起。
# 输入事件数据流动概览
cc 的另一个主要输入是用户输入事件,例如鼠标点击,鼠标滚轮和触屏手势。 输入事件是从 browser 进程转发到 renderer 进程中。 由 ui::InputHandlerProxy(实现 cc::InputHandlerClient 接口)负责处理。 其中一些输入事件在特定时间会被发送到 LayerTreeHostImpl(实现 cc::InputHandler 接口)。 这允许它修改活跃图层的属性树并根据需要滚动或缩放图层。某些输入事件无法在合成器线程处理(例如,存在需要同步调用的 Javascript 触屏或者滚轮事件处理器),因此这些输入事件将被转发到 Blink 去处理。 输入事件的数据流动路径跟上面的内容绘制的数据流动路径是刚好相反的。
# 提交流程
Commit 是一种从主线程推送数据到合成器线程的方式,并且保证了该过程中的数据完整性。 (cc 即使在单线程模式下运行,仍然需要通过 Commit 来推送数据到正确的数据结构)Commit 不是通过发送 ipc,而是通过阻塞主线程并复制数据的方式来完成提交。
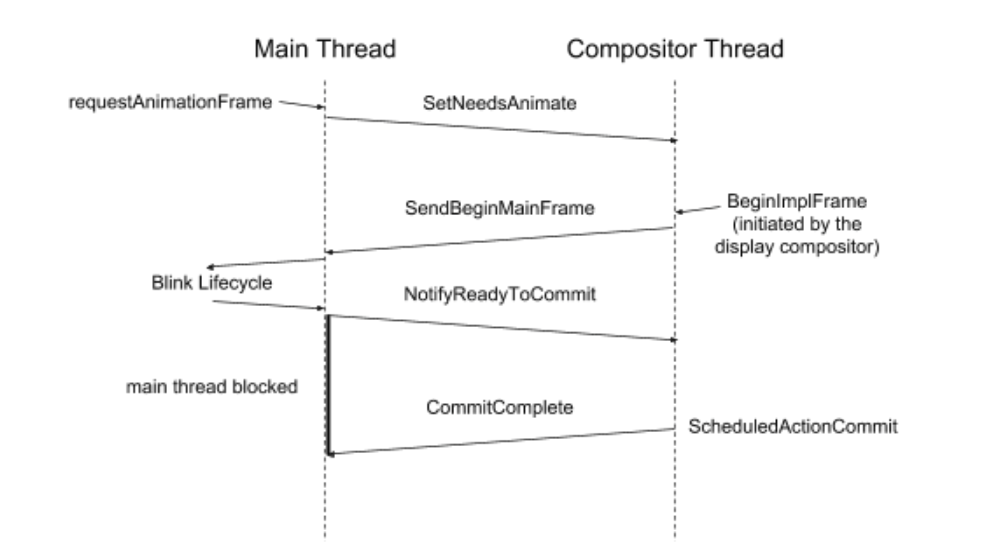
主线程可以通过多种方式请求提交。大多数网页都是通过 requestAnimationFrame 发起请求,最终在 LayerTreeHost 上调用 SetNeedsAnimate。此外,任何对 cc 输入的变更(例如,图层属性比如转换矩阵,或是对图层内容的更改),将会触发在 LayerTreeHost 上调用 SetNeedsAnimate,SetNeedsUpdate 或 SetNeedsCommit。不同的 SetNeeds 函数的作用是,如果确定没有实际发生变更,cc 可以在不同级别上提前终止提交流程。(例如,如果 requestAnimationFrame 回调没有改变图层,那么就不需要进行提交,甚至不需要更新图层。)如果不是调度器当前正在处理上一个提交流程的话,上述这些函数都会请求调度器发起新的 BeginMainFrame。 收到主线程请求后的某个时刻,调度器将调用 ScheduledActionBeginMainFrame 对请求进行响应。合成器线程会发送一个 BeginFrameArgs 到主线程启动 BeginMainFrame。 BeginFrameArgs 包含一个时间戳(用于动画目的),以及已经在合成器线程上应用的新增滚动增量(主要是处理用户滚动手势的结果),而 Blink 还不知道这些新的滚动位置。当 Blink 嵌入 cc 使用时,Blink 会在 BeginMainFrame 的过程中 获取新的合成器滚动增量,调用 requestAnimationFrame 回调,这些作业构成了 Blink 的渲染过程生命周期的一半。 完成此操作后,cc 将更新所有图层。如果在此更新流水线中的任何时刻,cc 确定不需要更多的工作(例如,合成器线程滚动更新到 Blink,但 Blink 处理该滚动过程中没有对页面进行任何更改),它就可以提前中止提交。(当前,单线程 cc 从不中止任何提交。)一旦 embedder 完成了 BeginMainFrame,并且提交没有中止,则 ProxyMain 将发送一个附带互斥锁的同步 NotifyReadyToCommit 消息给合成器线程,然后阻塞自己等待回应。 当调度器准备好提交时,它将调用 ScheduledActionCommit 进行响应。然后,合成器线程上的 ProxyImpl 会完成所有将数据从主线程(主线程此时被阻塞)复制到合成器线程对应数据结构的工作。然后它释放互斥锁,以便主线程可以继续运行。 ProxyImpl 是唯一可以访问主线程和合成器线程上数据结构的类。它只在主线程被阻塞时访问主线程上的 LayerTreeHost 和 Layers,并通过 DCHECK 断言进行线程检查。 ProxyMain 是存在于主线程上的对应物,由 LayerTreeHost 拥有。对于单线程情况,SingleThreadProxy 等同于 ProxyMain 加 ProxyImpl。
# 图层
图层是一个大小为整数的 2d 内容矩形。它还包括一些其它属性,比如矩阵变换,裁剪和特效,这些属性共同描述了它如何在屏幕上呈现。 cc 里面的图层有两个不同的类层次结构,一个用于主线程图层树(从 cc::Layer 派生),另一个用于合成器线程 pending,active 和 recycle 图层树(从 cc::LayerImpl 派生)。 它们基本上是 1:1 对应的,所以会同时存在 SurfaceLayer 和 SurfaceLayerImpl 或者 PictureLayer 和 PictureLayerImpl,因此本节讨论图层时并不加以强调是哪一种,可自行根据上下文判断。 在主线程上,图层是引用计数的。 LayerTreeHost 拥有根图层,每个图层以递归方式拥有其子图层。 Blink 的其他一些部分也可能是图层的提供者(例如,多媒体系统创建 surface 或 video 图层,插件),这是为什么主线程的图层要使用引用计数的原因。而在合成器线程上,图层是由其父节点使用 unique_ptrs 持有。
# 属性树
有两种方式可以在 cc 中描述属性的层次结构。传统的方式(ui/ 仍然使用这种方式)是以图层树的方式。如果父图层具有矩阵变换(例如,平移,缩放或透视),裁剪或特效(例如,模糊滤镜,或者 mask,或者半透明),则这些属性需要递归地应用于其子节点。这种组织方式在很多极端情况(固定位置图层,滚动父节点,滚动子节点)会导致糟糕的性能(需要大面积遍历这棵树并在所有步骤中计算所有属性)。 属性树是解决这个问题的一种方式。与上面的方式相反,cc 提供了单独的属性树:矩阵变换树,裁剪树,特效树。然后,每个图层都有若干节点 id,分别对应不同属性树上的矩阵变换节点,裁剪节点和特效节点。这样,属性更新的复杂度就是 O(感兴趣的节点)而不是 O(图层)。当存在属性树时,我们也不再需要图层树,而是可以使用有序的图层列表。
# PictureLayer
包含绘制内容的图层。 内容以 cc::PaintRecord 的形式表现。 PictureLayer 决定了对内容进行光栅化时使用的缩放比例。 每个缩放比例由一个 PictureLayerTiling 来表示,PictureLayerTiling 包含了一个特定缩放比例内容的稀疏 2d 平面分块集合。 分块集合中的每个分块就是一个 cc::Tile,它用于关联所对应矩形区域内的内容,分块的光栅化由 TileManager 管理。 如果在 DevTools 渲染设置中打开合成图层边框,则可以看到分块的边框。有许多启发式方法用于确定分块的大小,但对于软件光栅化分块大约为 256x256 像素,而对于 gpu 光栅化分块大致为 viewport width x 1/4 viewport height。 有许多启发式方法用于确定何时以及如何改变光栅化的缩放比例。 这些方法并不完美,你可以去改进它,不过风险自负。
[译注] 软件光栅化的分块大小一般由屏幕分辨率决定,1080p 的屏幕使用的是 384 x 384 的分块大小。
# PictureImageLayer
PictureLayer 的子类。 专门用于优化一个 元素自己拥有一个独立图层的特例。 如果图片元素拥有自己独立的合成图层并且没有边框或填充(也就是说图层绘制的内容与图片本身完全相同),则可以做一些额外的优化。它以固定的缩放比例“光栅化”图片,保证缩放此图片是高性能的。这种优化只用于软件光栅化,gpu 光栅化不需要使用 PictureImageLayer。
# TextureLayer
用于插件,canvas,这些图层内容的光栅化是自己负责而不是通过合成器的光栅化器,另外还有 WebGL。 这里的 “texture” 是指对 gpu 纹理的引用,但在使用软件合成的情况下实际上是共享内存位图。
# SolidColorLayer
如果已知图层仅为纯色,则无需光栅化该图层,也不需要分配 gpu 内存。这是对纯色图层这种简单图层的一种优化。
# VideoLayer
因为 surfaces for video project 的原因目前已经废弃。最终会被删除。
[译注] 顾名思义,原本是用于 video 元素。
# SurfaceLayer
一个 surface 图层拥有一个 surface id,用于表征系统中其它 compositor frames 的流。这是一种间接包含其它 compositor frame 生产者的方式。另见:surface 文档。 实际使用的一个例子是,Blink 通过 SurfaceLayer 嵌入对进程外 iframe 的引用。
# SolidColorScrollbarLayer
Android 的滚动条是一个 “纯色” 滚动条图层。它们就是一个简单的矩形,可以由合成器直接绘制,而无需为它们创建纹理资源。 同时存在纯色和滚动条绘制图层的原因是,在合成器线程上处理滚动可以即时更新滚动条而无需回到主线程处理。 如果不区分处理,即使页面的滚动很流畅,但滚动条本身的移动则变得不够平滑。
# Painted(Overlay)ScrollbarLayer
桌面版本(非 Android)的滚动条是有绘制内容的滚动条。因为主题样式代码不是线程安全的,所以滚动条和滚动轨道在主线程上绘制并光栅化为位图。然后,这些位图再在合成器线程上通过生成对应的 quads 进行绘制。ChromeOS 使用 PaintedOverlayScrollbarLayer,这是一个使用 nine-patch 位图的版本。
# HeadsUpDisplayLayer
这个图层是用于支持 devtools 的渲染设置。它用于绘制 FPS 仪表,另外也用于绘制一个表示绘制更新或变更区域的覆盖层。这个图层比较特殊,因为它的输入取决于所有其他图层的 damage 计算,所以必须最后更新。
# UIResourceLayer / NinePatchLayer
UIResourceLayer 是与 TextureLayer 等效的软件位图版本。它处理位图上传纹理并在上下文丢失时根据需要重新创建它们。 NinePatchLayer 是一个派生的 UIResourceLayer 类,它将 UIResource 切割成可伸缩的部分。
# 树:commit/activation
图层树有四种类型,但在任何给定时间只存在 2-3 种:
- 主线程树(cc::Layers,主线程,始终存在)
- Pending 树(cc::LayerImpl,合成器线程,用于光栅化阶段,可选)
- Active 树(cc::LayerImpl,合成器线程,用于绘制阶段,始终存在)
- Recycle 树(cc::LayerImpl,合成器线程,与 Pending 树不会同时存在)
这些被称为“树”,因为历史上它们一直是树结构,它们存在于 cc/trees/ 目录下,但它们目前实际上是列表而不是树(抱歉)。主线程的图层树由 LayerTreeHost 拥有。 pending,active 和 recycle LayerImpls 树都是 LayerTreeHostImpl 拥有的 LayerTreeImpl 实例。 Commit 是将图层树和属性从主线程图层列表推送到 pending 树的过程。Activation 是将图层树和属性从 pending 树推送到 active 树的过程。在上述的两个过程中,都会创建一个重复的图层结构(具有相同的图层 id,图层类型和属性)。图层 id 用于查找每棵树上的相应图层。主线程树上 id 为 5 的图层数据将推送到 pending 树上的 id 为 5 的图层。pending 树上的该图层将推送到 active 树上 id 为 5 的图层。如果该图层还不存在,则在推送期间将创建该图层。类似地,源树中不再存在的图层将从目标树中删除。这一切都是通过树同步过程完成的。 因为 Layer(Impl) 的分配是昂贵的并且大多数图层树结构不会每一帧都发生变化,所以我们激活 pending 树后,原来的 pending 树就变成 “recycle 树”。除了作为最后一个 pending 树的缓存外,此树没有其它用途。这避免了从主线程推送数据到 pending 树时额外的图层分配和属性赋值的工作。这仅仅是一种优化。 pending 树存在的原因是,如果单个 Javascript 调用过程中的网页内容有多处更改(例如,html canvas 上画了一条线,并且移动了一个 div,还将某些元素背景颜色更改为蓝色),这些都必须以原子方式一次性完整地呈现给用户。 Commit 会对这些更改进行快照并将它们推送到 pending 树中,以便 Blink 可以继续更新主线程图层树以供将来提交。提交后,这些更改需要重新光栅化,并且必须先完成所有光栅化,然后才能向用户呈现新的内容而不是一个部分分块区域的更新。pending 树是用于等待所有异步光栅化工作完成的暂存区域。当 pending 树用于完成下一帧所需的所有光栅化工作时,active 树仍然可以被动画和滚动更新,保证用户得到即时的响应。 单线程版本的 cc 没有 pending 树,主线程提交的数据直接推送到 active 树。(此模式下不使用 recycle 树。)这是一种避免额外工作和拷贝的优化。为了解决原子性呈现的问题,active 树会强制可见区域内的所有分块都光栅化完毕后才能进行绘制。不过,鉴于这是 cc 的单线程版本,不需要处理合成器线程动画或滚动,由合成器本身发起的重绘请求其实很少。
# 光栅化器和分块管理
TileManager 负责光栅化所有的分块。每个 PictureLayer 都提供了一组用于光栅化的分块,其中每个分块都是在特定缩放比例下的绘制内容的子矩形。 TileManager 找到在 active 树上当前绘制所有需要的分块,和所有需要激活 pending 树的分块,另外还有靠近 viewport 但暂时还不可见相对低优先级的分块,以及需要解码的屏外图片。 目前 cc 有三种不同的光栅化器: 软件光栅化器:光栅化器生成软件位图 gpu 光栅化器:通过 command buffer 发送 gl 指令生成 gpu 纹理 oop 光栅化器:通过 command buffer 发送 2d 绘制指令生成 gpu 纹理 TileManager 根据用于提交 compositor frames 的 LayerTreeFrameSink 是否具有 context provider,来选择软件光栅化或者是 gpu/oop 光栅化。它始终处于其中一种模式。切换模式需要释放所有的分配资源然后重新光栅化。GPU 光栅化器目前已经逐步弃用,最终将在所有情况下由 OOP(进程外)光栅化器替代。切换模式的一个常见原因是 gpu 进程崩溃太频繁,Chrome 将不得不将光栅化和合成都从 gpu 切换到软件的模式。 一旦 TileManager 确定了下一个要完成的工作集,它就会生成一个包含任务依赖关系的 TaskGraph,然后跨多个 worker 线程进行任务调度。TaskGraphs 不会动态更新,而是整个 graph 会被重新调度。一旦开始运行的任务是无法被取消的。但是已经进入调度还未开始运行的任务,如果新提交的 graph 不包含这些任务,这些任务会被自动取消。
# 图片解码
图片解码在 TileManager 中有很多需要特殊处理的地方,因为它们是光栅化中耗时最长的部分,特别是相对于性能较好的 gpu 光栅来说。 在 task graph 里面,每个图片的解码都有自己独立的解码任务。 软件光栅化与 gpu 光栅化使用不同的解码缓存。 SoftwareImageDecodeCache 管理解码,缩放和颜色校正,而 GpuImageDecodeCache 进一步需要将解码后的位图上传到 gpu 进程生成纹理,使用 gpu discardable memory 来缓存纹理。 cc 还处理 Chrome 中动画 gifs 的所有动画。 当 gifs 动画时,它们会生成一个新的 pending 树(由合成器线程直接生成而不是主线程提交),包含一些需要重新光栅化的区域,然后重新光栅化该 gif 覆盖的分块。
# Raster Buffer Providers
除软件与硬件光栅化模式外,Chrome 还可以在软件与硬件显示合成模式下运行。 Chrome 从不将软件合成与硬件光栅化混合,但光栅化模式 x 合成模式的其他三种组合都是有效的。 合成模式影响 cc 提供的 RasterBufferProvider 的选择,它管理在光栅化工作线程上的光栅化过程和资源管理: BitmapRasterBufferProvider:用于软件合成,使用软件位图作为光栅化的目标缓冲区 OneCopyRasterBufferProvider:用于 gpu 合成,光栅化的软件位图使用(跨进程)共享内存,然后在 gpu 进程中上传成纹理 ZeroCopyRasterBufferProvider:用于 gpu 合成,光栅化的软件位图使用 GpuMemoryBuffer(例如IOSurface),可直接被 display compositor 使用 GpuRasterBufferProvider:用于 gpu 合成,通过 command buffer 发送 gl(用于 gpu 光栅化器)或者 paint 指令(用于 oop 光栅化器),使用 gpu 直接光栅化到 gpu 纹理 需要注意的是,由于需要在光栅化过程中锁定上下文,gpu 和 oop 光栅化目前不支持多线程并发运行,不过图片解码仍然可以在其他线程上并发进行。这个单线程限制是通过加锁解决的,而不是线程亲和性。
[译注] GpuMemoryBuffer 是一种平台相关的特殊缓冲区的封装,比如 IOSurface,它们即可以被 cpu 也可以被 gpu 直接访问,在 Chrome 里面一般是 cpu 写(光栅化),gpu 读。
# 动画
animation/ 目录实现了一个动画框架(由 LayerTreeHost(Impl) 通过 cc::MutatorHost 接口使用)。该框架支持基于关键帧的矩阵变换列表,半透明和其它 filter 效果列表动画,这些动画直接操作属性树中对应 TransformNode/EffectNode 上的值(由ElementId标识)。 动画由一个动画实例表示,动画实例具有一个(将来或许更多)KeyframeEffects,每个 KeyframeEffects 都有多个 KeyframeModel。动画管理动画的播放状态,开始时间等,KeyframeEffect 表示动画的目标元素,而每个 KeyframeModel 描述动画作用于元素上的特定属性(例如矩阵变换/透明度/filter 等)。动画的来源可以是 embedder(例如,一个矩阵变换的 Blink 动画),或者它可以是来自 cc 本身(例如,用于平滑滚动的滚动动画)。 LayerTreeHostImpl 向 AnimationHost 通知添加新元素和删除旧元素,从而引发作用于这些元素的动画的状态更新。它调用 NeedsTickAnimations 来了解是否应该继续调度动画,并且每帧的 TickAnimations 调用会更新动画时间戳,状态,产生动画事件,以及根据动画更新属性树节点的实际输出值。
# cc/paint/
此目录存放用于描述绘制内容的类。它们与 Skia 里对应的数据结构非常相似,但在所有情况下都是可变的,内省的和可序列化的。它们还需要处理 Skia 不需要考虑的安全问题(例如 TOCTOU 问题,一块用于序列化绘制内容供 gpu 进程访问的共享内存可能会被一个已经溢出的恶意 renderer 所改写)。 PaintRecord(又名PaintOpBuffer)是 SkPicture 的等价物,用于存储 PaintOps。 PaintRecord 可以由 raster buffer provider 光栅化为位图或 gpu 纹理(使用软件或 gpu 光栅化器),也可以被序列化(使用 oop 光栅化器)。 PaintCanvas 是记录绘图命令的抽象类。 它可以由 SkiaPaintCanvas 实现(使用 SkCanvas 完成绘制)或 PaintRecordCanvas 实现(将绘制指令存储到 PaintRecord)。
# 调度
cc 的工作由 cc::Scheduler 来驱动。这是 Chrome 众多调度器之一,其它还包括 Blink 调度器,viz::DisplayScheduler,浏览器 UI 任务调度器和 gpu 调度器。 cc::Scheduler 由 ProxyImpl(或SingleThreadProxy)拥有。它接收各种输入(可见性,帧开始消息,重绘请求,准备绘制,准备激活等)。这些输入驱动 cc::SchedulerStateMachine,然后决定了 SchedulerClient(LayerTreeHostImpl)要采取的操作,例如 “Commit” 或 “ActivateSyncTree” 或 “PrepareTiles”。这些操作的触发依赖于当前状态,它们通常是流水线里面耗时较长的部分,我们需要小心避免频繁调用。 cc::Scheduler 代码区分不同的 begin frames,display compositor 发送的 begin frames 是 BeginImplFrame(即 cc 应该生成 compositor frame),发送给它的 embedder 的 begin frame 是 BeginMainFrame(即,cc 应该告诉 Blink 运行 requestAnimationFrame 并产生一个提交,或者在浏览器中 cc 应该告诉 ui 做类似的事情)。 BeginImplFrame 由 viz::BeginFrameSource 驱动,后者又是由 display compositor 驱动。 在一次低延迟和光栅化足够快的流水线更新中,一般调度流程是 BeginImplFrame - > BeginMainFrame - > Commit - > ReadyToActivate - > Activate - > ReadyToDraw - > Draw。 但是,如果光栅化速度很慢,cc 可以在激活之前就可能发送第二个 BeginMainFrame,并且它将在 NotifyReadyToCommit 中阻塞,直到激活完成,因为如果当前的 pending 树还没有被激活,SchedulingStateMachine 将阻止启动提交。这允许主线程并行地去生成下一帧,而不是以延迟为代价而处于空闲状态。在光栅化速度不够快时,一个可能的调度排序是: BeginImplFrame1 - > BeginMainFrame1 - > Commit1 - >(slow raster) - > BeginImplFrame2 - > BeginMainFrame2 - > ReadyToActivate1 - > Activate1 - > Commit2 - > ReadyToDraw1 - > Draw1。 cc::Scheduler 维持一个期望其 embedder 响应的截止时间。如果主线程响应缓慢,则调度器可以在不等待提交的情况下进行绘制。如果发生这种情况,则认为调度器处于高延迟模式。如果未来的帧生成再次开始变快,则调度器可以尝试跳过 BeginMainFrame 以“赶上”并重新进入低延迟模式。高延迟模式通过增加延迟来加大流水线的吞吐量。调度器通过保存历史时间戳来区分不同的模式,并试图用启发式的方法进行调整。
# Compositor frames, render passes, quads
cc 的输出是 compositor frame。compositor frame 由元数据(设备缩放比例,颜色空间,大小)和一组有序的 render passes 组成。一个 render pass 包含一组有序的 quads,quads 包含对资源的引用(例如 gpu 纹理)以及有关如何绘制这些资源的信息(大小,缩放比例,纹理坐标等)。一个 quad 是绘制到屏幕上的一个矩形,可以通过开启合成图层边框可视化来查看这个矩形。图层本身通过覆写 AppendQuads 函数来生成 quads。它将生成一组 quads,刚好覆盖(不重叠或相交)图层的可见区域。
有各种类型的 quads 大致对应于不同的图层类型(ContentDrawQuad,TextureDrawQuad,SolidColorDrawQuad)。由于一个图层可以生成许多 quads(即 PictureLayerImpl),这些 quads 的部分信息是相同的,我们使用 SharedQuadState 来优化这些共享信息的内存占用。RenderSurfaceImpls 跟 render passes 是 1:1 的对应关系,它的 AppendQuads 的逻辑跟图层生成 quads 大致相同 ,用于生成 RenderPassDrawQuads。
# Render Pass
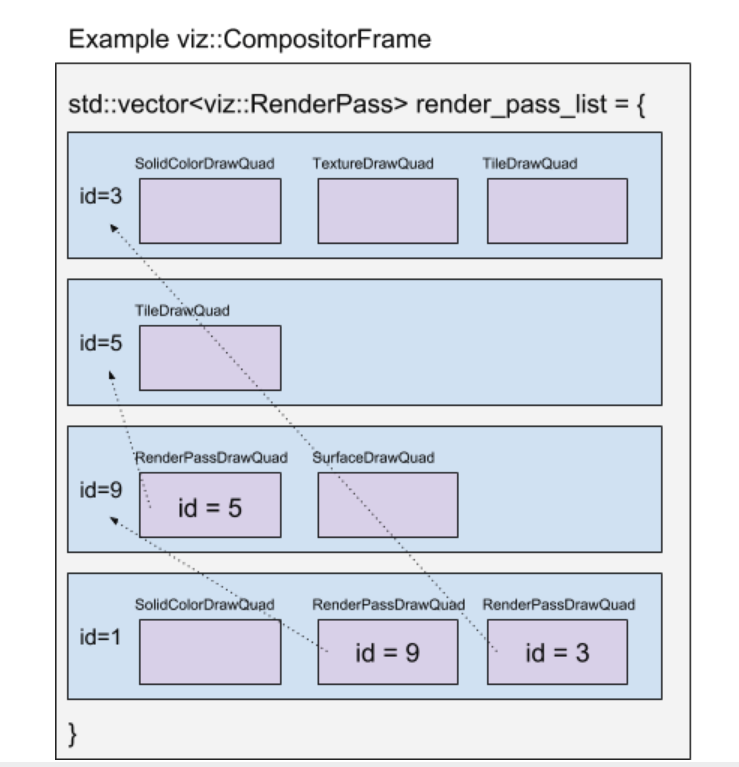
render pass 的存在是为了实现合成特效(请参阅:特效树)。有些特效需要先合成到 render surface 后才能实现。另外也可能是先合成再实现这些特效会更简单(因为特效可以直接在单个 render pass 产生的纹理上应用,而不是应用在一棵图层子树产生的任意的 quads 集合上)。render passes 的常见例子是:masks,filters(例如模糊),裁剪旋转后的图层或一棵内容子树的半透明效果。 在 compositor frame 内,render passes 和 render passes 中的 quads 是有序的。render passes 列表是一个展平后的列表,用于表示 render passes 的依赖关系树。如果 render pass 1 依赖于 render pass 9(因为它包含一个 RenderPassDrawQuad,引用了 9 的输出),那么在列表上 9 将出现在 1 之前。因此,root render pass 始终位于列表的最后。在单个 render pass 中,quads 按底部到顶部的顺序排列(画家算法)。 通常,quads 不被认为是存在于 3d 空间中(即使通过三维矩阵变换进行变换),它们仍然按顺序绘制,一个 quad 绘制到在它之前绘制的 quad 之上。但是有一种模式,其中一组 quads 可以在一个 3d 上下文中(由 css transform-style:preserve-3d 引起)。这时我们使用 BSP 树在同一个 3d 上下文中对它们进行排序和相交检查。
# 术语表
参见: cc/README.md
# 其它资源
相关的演示稿,视频和设计文档: https://www.chromium.org/developers/design-documents/chromium-graphics
# 找不到合适归类的各种杂项
# Damage
Chrome 在整个系统的不同模块里都有各种不同的 invalidation 的概念。 “Paint invalidation” 是需要在 Blink 中重新绘制的部分 document(DOM 节点)。 “Raster invalidation” 是已发生变更并需要重新光栅化的图层的一部分(可能是由于 paint invalidation,也可能是合成失效,例如图层第一次被光栅化或者纹理被丢弃然后再次需要时) 。最后,damage 是 “draw invalidation” 的另一种表述方式。表示屏幕的一部分需要重新绘制。 有两种类型的 damage:invalidation damage 和 expose damage。Invalidation damage 是由于 raster invalidation 造成的,其中纹理的一部分内容已经改变并且屏幕需要更新显示。Expose damage 是指图层消失,第一次被添加或者图层的层叠顺序发生变化。在这些情况下虽然没有发生重新光栅化,但仍需要更新屏幕。 cc 通过 DamageTracker 来计算 damage,并将其与 CompositorFrame 一起发送。需要 damage 的一个原因是 display compositor 可用于局部缓冲区交换优化(此时仅仅更新屏幕的一部分),这种方式可以减少了耗电。另一个原因是当使用硬件覆盖层时,display compositor 可以知道只有覆盖层被更新而不必重新合成场景的其余部分。
# Mask 图层
Mask 图层是用于实现蒙版效果的图层。他们不在图层树里面,没有父亲节点。它们由应用蒙版的图层所拥有。 它们可以是任何类型的图层子类(例如 PictureLayer 或 SolidColorLayer)。 任何时候遍历图层,它们都是需要考虑的特殊情况,因为它们不是普通父/子树结构的一部分。虽然它们在光栅化和分块管理方面与其他图层一样,但是它们的 AppendQuads 调用是通过额外 RenderSurfaceImpl, 而不是顶层的图层遍历,这是因为它们是用于绘制特效而不是绘制自身的内容。
# "Impl" 后缀
cc 使用 “impl” 后缀... 但是涵义与 Chrome 的其它模块或软件工程常用的普遍涵义并不一样。 在 cc 中,“impl”表示该类在合成器线程上使用,而不是在主线程上使用。 这样做的历史原因是,cc 在设计时,我们在主线程上有 Layer,我们需要一个运行在合成器线程上等价的类。jamesr@ 咨询了 nduca@,他提出了一个非常合乎逻辑的论点,即合成器线程上的东西是合成器内部的,并且实际上是主线程版本的实现,所以我们就从 Layer 得到了 LayerImpl。参见:https://bugs.webkit.org/show_bug.cgi?id=55013#c5 然后,如果你需要一个LayerImpls 树,LayerTreeImpl 就出现了,而拥有和管理这些树的对象就被命名为 LayerTreeHostImpl。突然之间,“impl 线程” 就演变成所有 “impl 类” 存在的线程。如果你将光栅化移动到合成器线程,那么就会很诡异地被称为 “impl-side painting”。
